MeshLRM: Large Reconstruction Model for High-Quality Meshes
Abstract
We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation.
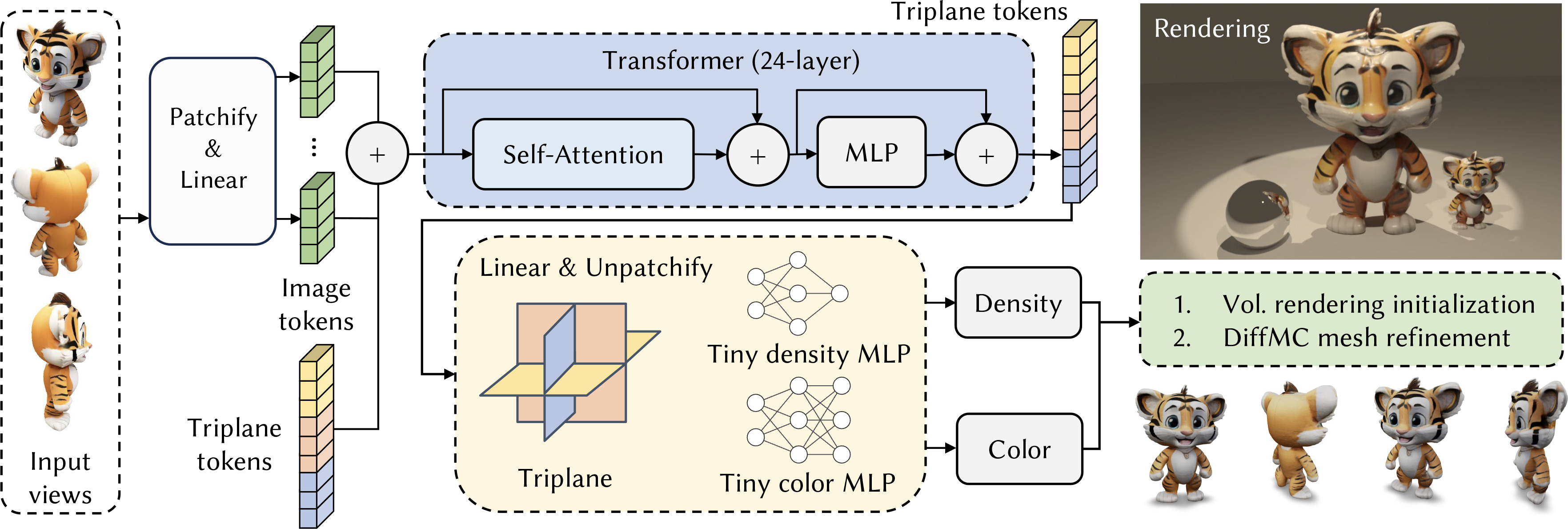
Pipeline: The model architecture of MeshLRM. The images are first patchified to tokens. The transformer takes the concatenated image and triplane tokens as input. The output triplane tokens are upsampled with the unpatchifying operator while the output image tokens are dropped (not drawn in figure). With two tiny MLPs for density and color decoding, this model supports both the volumetric rendering and the DiffMC fine-tuning. We render our final mesh output on the rightmost of the figure.
GSO dataset






ABO dataset






OpenIllumination dataset



Text-to-3D
Note: We use Instant3D for text-to-multiview generation.



Image-to-3D
Note: We use Zero123++ for image-to-multiview generation.



BibTeX
@article{wei2024meshlrm,
title={MeshLRM: Large Reconstruction Model for High-Quality Mesh},
author={Wei, Xinyue and Zhang, Kai and Bi, Sai and Tan, Hao and Luan, Fujun and Deschaintre, Valentin and Sunkavalli, Kalyan and Su, Hao and Xu, Zexiang},
journal={arXiv preprint arXiv:2404.12385},
year={2024}
}